Mi sono quasi emozionato leggendo un articolo su Wired che tocca una questione centrale nello sviluppo del Web, ma di cui non sentivo quasi più parlare da quando sono uscito dall’università.
L’articolo di per sé tratta di interfacce vocali, sottolineando il ruolo che ha giocato un’impresa come Evi per rendere Alexa capace di dare risposte utili. Probabilmente non è il primo sul tema, né il più ricco di dettagli, ma ha il pregio di accostare in maniera per me profondamente ispiratrice due piani rispetto ai quali ho affinato la mia sensibilità negli anni:
- la progettazione dell’esperienza utente (UX design)
- e la produzione di informazioni usabili direttamente dalle macchine — come un’Alexa appunto, o un Assistente di Google, una Siri — ossia la rappresentazione della conoscenza (Knowledge Representation)
In questo mio articolo do un primo sfogo al mucchio di riflessioni e idee nascenti che sono scattate dopo quella lettura, contaminandosi ovviamente con altro materiale che ho divorato per l’improvvisa fame di approfondimenti.
Mi riprometto di affrontare in articoli successivi, in modo ben più compiuto, tutti i temi che qui metto in fila semplicemente per abbozzare uno scenario ed evocarne degli sviluppi interessanti.
L’avvento delle interfacce vocali
Gli assistenti virtuali con cui interagire attraverso comandi vocali e risposte da ascoltare vanno affermandosi rapidamente. Stando a una ricerca di NPR con Edison Research, negli USA le vendite di smart speaker sono cresciute del 78% nel 2018 rispetto all’anno precedente.

Non ho sotto mano dati specifici per l’Italia, ma vedo anche dalle nostre parti un interesse crescente per questi articoli. È vero che la mia cerchia di conoscenze può essere un campione poco rappresentativo della società italiana. Ma se considero quanto stanno puntando su questo tipo di interazione i colossi del Web e i produttori di smartphone, mi sembra che la via sia segnata.
Nuovi dispositivi, nuove esigenze
Le interfacce vocali presentano una serie di nuove sfide ai designer. Il flusso d’interazione deve essere più lineare che su uno schermo (desktop o mobile che sia) e più breve. Per quanto vogliano prestarsi a simpatici siparietti in caso di interrogazioni singolari, gli Assistenti virtuali non sono (ancora) compagni ideali per gradevoli conversazioni.
Quando usa un’interfaccia vocale, l’utente:
- deve fare affidamento sulla sua memoria per scegliere tra le diverse opzioni che l’Assistente propone ad ogni passaggio (quant’è fastidioso quando il “disco” di un servizio telefonico ha un’opzione per tutti e 12 i tasti del tastierino?)
- non può ricordare tutte le alternative che ha tralasciato in ognuno dei passaggi precedenti
- non ha modo di tornare rapidamente a un passaggio precedente
- ha a che fare con un interlocutore poco abile a
- ri-tracciare i riferimenti anaforici verso scambi precedenti
- interpretare il contesto fattuale dell’utente
In breve, l’interazione dialogica toglie molto controllo all’utente e, per essere davvero efficace, richiede un grande affinamento della capacità dell’assistente di fornire le risposte “giuste” alle sue richieste.
Per farsi un’idea dei limiti percepiti degli assistenti virtuali di oggi si può considerare questo studio di N/N Group.
Il bisogno di risposte esatte
Ma qual è la risposta giusta alla richiesta di un utente?
Un primo approccio per chiarirci è a metà tra epistemologia ed etimologia. Più che le risposte giuste, all’utente servono le risposte esatte. Sembra una sottigliezza, ma non lo è: la risposta esatta, alla lettera, è semplicemente la risposta che si esige, quella che si vuole ottenere.
Questa finezza da fanatici del vocabolario implica ricadute che si capiscono meglio con qualche esempio.
Comandi vocali per la casa
Gino ama stare molto comodo e in casa gira sempre scalzo, in pantaloncini e maglietta. Quando rientra da lavoro, anche in pieno inverno, si mette subito in questa tenuta da casa e comanda a Google Home di alzare il riscaldamento rispetto alla temperatura a cui l’aveva lasciato Gina, la compagna di Gino.
La risposta esatta — desiderata da Gino — in questo caso è che l’Assistente provveda a far lavorare di più la caldaia. Da un punto di vista economico, ecologico e magari anche etico, però, sarebbe molto più giusta una risposta impertinente del tipo “Perché piuttosto non ti copri un po’ di più?”.
Suggerimento di un locale
Gina vuole uscire con le vecchie amiche dell’università che non vede da tempo. In memoria dei bei tempi andati desidera portarle in qualche locale alla moda, con buon cibo giapponese, ma non troppo costoso. Questo è tutto ciò che ha in mente quando chiede al suo Assistente di trovarle il “miglior ristorante giapponese in città”.
La risposta giusta in assoluto su quale sia il miglior ristorante giapponese non esiste: entrano in gioco troppi criteri dipendenti da gusti personali. Ma la risposta esatta (desiderata da Gina) è sempre possibile, a patto che l’Assistente di Gina abbia accesso al suo (di lei) modello mentale corrente, in base al quale “migliore” significa alla moda ma non troppo costoso.
Questione di pertinenza
Da punti di vista opposti, entrambi gli esempi mettono in luce lo stesso nodo: la difficoltà per un Assistente virtuale di raccogliere e sfruttare informazioni essenziali sul conto del proprio utente-padrone. Proprio quelle informazioni che permetterebbero di osservare la massima griceana della pertinenza, che richiede di
Essere pertinenti all’argomento di cui si parla.
(Paul Grice)
e che permetterebbe di portare le interazioni vocali a tutto un altro livello.
Nel caso di Gino, la risposta impertinente nei modi sarebbe molto pertinente nei fatti, soprattutto se un Assistente virtuale, in prospettiva, dovesse diventare una sorta di maggiordomo, fidato collaboratore domestico che magari ci aiuta a gestire al meglio la casa a tutto tondo, invece che soltanto una servizievole prolunga delle nostre mani.
Nel caso di Gina, una risposta effettivamente pertinente sarebbe il risultato di una qualche euristica che facesse scegliere direttamente all’Assistente il ristorante adatto per quella serata, conoscendo sufficientemente bene i gusti di Gina e soprattutto cosa lei intende quella sera per “ristorante migliore”.
Bisogno di conoscere
Gli Assistenti virtuali, dunque, hanno bisogno di conoscere. Di un sistema che permetta loro di apprendere cose sui loro utenti-padroni. Questo non può essere il tipo di apprendimento da algoritmi di machine learning, che hanno bisogno di grandi quantità di dati su cui essere addestrati per imparare a far bene una singola funzione. Al contrario, è l’apprendimento di tanti piccoli pezzi puntuali di informazione, la cui validità può anche essere molto limitata nel tempo, e che quindi non può derivare da sessioni e sessioni di addestramento.
È invece, per esempio, il tipo di conoscenza codificata nei Knowledege Graph. Ossia collezioni di informazioni formulate esplicitamente per essere usabili dalle macchine. Quelle che permettono ad Alexa di rispondere con precisione alla domanda “Quanti abitanti ha Roma?”. Il modo in cui un utente qualunque possa istruire il proprio Assistente virtuale sui fatti suoi, però, non è affatto banale.
Rappresentare la conoscenza
Finché si tratta di informazioni relativamente stabili e potenzialmente utili per motitudini di utenti, lo sforzo si può anche pensare di affrontarlo con successo. È il caso di società come Evi (di cui dicevamo sopra) che per anni hanno macinato fatti e fattarelli per alimentare motori di ricerca specializzati proprio a dare le risposte esatte a domande enciclopediche. Società che poi vengono rilevate dall’Amazon o Google di turno appena raggiungono livelli interessanti di compiutezza — o almeno quando sono riuscite a dimostrare efficacia e sostenibilità del loro approccio.
Quale sforzo è necessario?
Relativamente recente (settembre 2018) è la notizia del primo knowledge graph dedicato a un personaggio pubblico: Noam Chomsky. Dopo averlo scelto per la sua estrema prolificità intellettuale — che lo ha reso presumbilmente l’autore più citato al mondo — un paio di Compagnie attive nello sviluppo di prodotti e servizi per il Web dei dati ambiscono a mettere insieme tutte le “idee” di Chomsky, potendo mostrarne le evoluzioni nel tempo e localizzandole nei vari testi che le esprimono. Dopo mesi di lavoro non mi risulta sia stato ancora completato.

Visto lo sforzo che serve per produrre il Knowledge Graph di un singolo individuo (sia pure Noam Chomsky) da parte di professionisti del mestiere, certo appare un’impresa improponibile quella di rappresentare e trasferire efficacemente tutto lo scibile su una persona qualsiasi (biografia, aneddoti, interessi, abitudini, gusti, preferenze, amicizie, parentame e quant’altro) per dare al suo Assistente virtuale la conoscenza di cui ha bisogno.
Altri approcci possibili
Vista la non praticabilità di questa via per ogni singolo fattarello personale, credo che qui si apra la vera sfida per i designer delle interfacce vocali di domani. Generare flussi di interazione leggeri, gradevoli, ma dai quali l’Assistente giorno dopo giorno acquisisce informazioni preziose sul suo utente-padrone. Senza tediare mai con lunghe sessioni di domande, ma come un buon amico, imparando ad ascoltare e presentare al momento opportuno una o poche domande pertinenti.
Per riuscirci, l’Assistente dovrebbe avere una sorta di schema di profilo personale dell’utente, da compilare nel corso delle sue interazioni, e tentare di volta in volta di riempire qualche casella. L’efficacia di questa progressiva scoperta dell’utente dipende direttamente dalla bontà dello schema in cui l’Assistente va a registrare via via le informazioni che raccoglie.
Interazioni guidate dalla conoscenza
Lo schema di riferimento, infatti, può essere piuttosto banale o mostruosamente complesso. Se penso a uno schema banale mi viene in mente la “carta di identità” dei bambini che ogni estate mia cugina doveva rifarmi: colore preferito, animale preferito, gusto di gelato preferito e così via.
Ci vorrebbe poco, in fin dei conti, a produrre uno schema banale, ma ne risentirebbe l’interazione: schema banale -> domande banali -> interazioni banali. E poche occasioni in cui l’Assistente è in grado di prendere l’iniziativa.
Viceversa, con uno schema complesso si moltiplicano le possibilità per un Assistente di essere propositivo, di domandare per acquisire maggiori informazioni e, di conseguenza, di trovare cose interessanti da proporre all’utente, anche più pertinenti e utili di un “Potrebbe piacerti anche questo” che spinge sfacciatamente il cross selling durante un acquisto.
Il Web come dev’essere
Perché tutto questo mio sproloquio? Dicevo che mi sono quasi emozionato a leggere l’articolo su Wired. Perché mi ha fatto fare un tuffo nel passato.
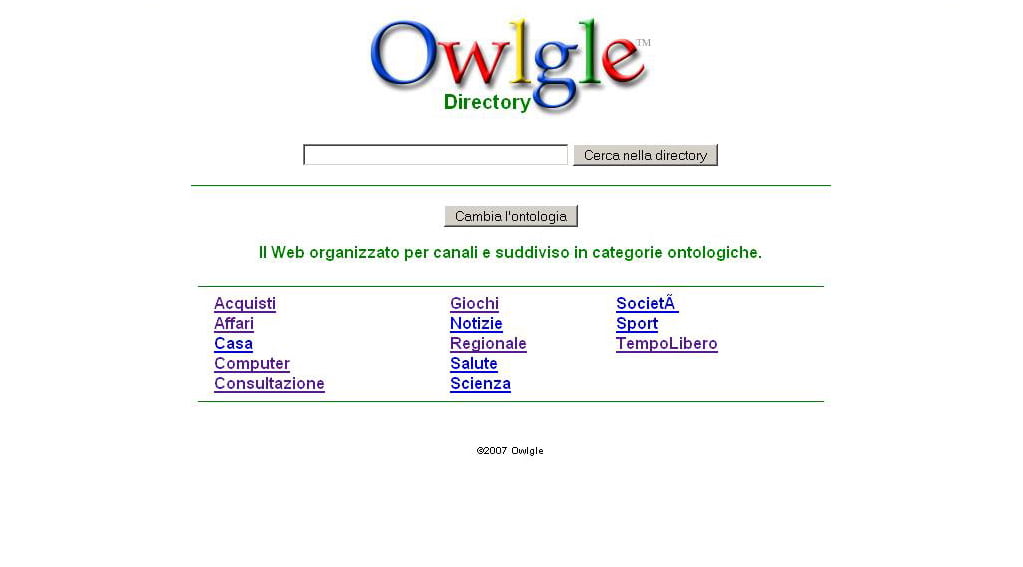
In realtà mi occupavo di queste cose già 14 anni fa, quando ho incontrato le “ontologie”. E di lì a un paio d’anni ho fantasticato nella mia tesi per la laurea specialistica di un sistema di directory — ah, Yahoo! andava ancora forte, ma l’avevo chiamato Owlgle 🙂 — in cui caricare la propria “visione del mondo” racchiusa in una ontologia, e attraverso il quale poter esplorare il Web in modo coerente con quella.
All’epoca non consideravo le questioni di usabilità, anche se avevo studiato Gibson, per dire. Di fatto, non tenevo in conto una concreta realizzazione di un sistema del genere. Per me poteva anche restare in capo all’utente caricare nel motore di ricerca la propria ontologia, possibilmente in formato OWL, ma in alternativa anche in RDF per essere generosi. Mi interessava più che altro l’idea di fondo: un Web dove non solo le pagine sono collegate tra loro, ma anche le informazioni. E le macchine non danno accesso a una pagina dopo l’altra, ma acquisiscono le informazioni seguendone le connessioni e forniscono direttamente le risposte che servono.

Dal mio punto di vista, stavo semplicemente procedendo in maniera lineare dalle idee dell’inventore del Web (Tim Berners-Lee, in caso di dubbi). D’altro canto anche le sue idee, già chiaramente espresse nel 1999 in Weaving the Web, hanno avuto bisogno di lunghi anni prima di prendere una forma riconoscibile nella trama del Web di questi tempi.
Logica e interazione
A lungo, infatti, l’idea di un Web dei dati (e metadati) soggiacente al Web delle pagine consumabili dalle persone è rimasto un tema per pochi addetti ai lavori, principalmente raccolti in centri di ricerca. Perfino le big Company del web hanno lasciato andare in avanscoperta piccole imprese, per poi acquisirle quando hanno visto che effettivamente la strategia poteva funzionare.
Ora vedo uno scenario in cui tutto questo, anche la mia fantasia di Owlgle, può prendere realmente corpo. Manca una parte però: gli schemi. Ciò che deve raccogliere le diverse biografie e “visioni del mondo” dei singoli utenti e comporle mettendole in relazione una con l’altra. Il livello logico che dà senso alle informazioni codificate in tanti piccoli o grandi Knowledge Graph per metterli insieme e permettere scambi continui di conoscenza. Conversazioni. Tra gli Assistenti e i loro utenti-padroni, ma anche tra Assistenti e Assistenti.
È qui che servono persone capaci di modellare gli schemi (grafi) e progettare le strutture in grado di confrontarli tra loro (ontologie) per consentire a macchine come gli Assistenti virtuali di interagire tra loro.
Avete visto l’anno scorso (al Google I/O ’18) la dimostrazione della telefonata dell’Assistente di Google per prenotare un appuntamento dal parrucchiere? Ecco, immaginate che non ci sia neanche la parrucchiera a rispondere, ma un altro Assistente. E a quel punto non serve neanche far squillare il telefono: fanno tutto tra loro attraverso il Web. Come diceva Tim-Berners Lee. Nel 1999.